Hi,
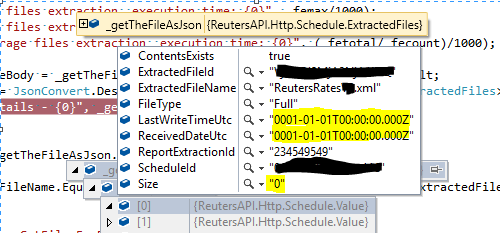
We are using the DSS Reuters Rest API to download rates file. We have seen that 'LastWriteTimeUtc' in the result of a call to 'report extractions' has come back with the min value of (01/01/0001 00:00:00 +00:00) for DatetimeOffset for 'LastWriteTimeUtc' for both the .notes and .xml files.
We have seen from the extracted files notes that it took over 4 minutes for processing to be completed.
In a case like this, where files take a long time to be processed, do Reuters populate fields like 'LastWriteTimeUtc' with default values?
-------------------------------------
Edit:
We are making the following calls to download the content of a rates xml file:
1. Authentication:
POST https://hosted.datascopeapi.reuters.com/RestApi/v1/Authentication/RequestToken
We pass in credentials and receive a token back which we pass in in all subsequent calls.
2. LastExtraction:
We pass in appropriate schedule id for the given file and we receive a response, from which we take the report extraction id to use in the next call.
3. Files:
GET https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/ReportExtractions('111111')/Files
We pass in the extraction id from previous call. We receive the files data associated with last extraction. The files are: the rates file and notes. We spool through the file data and get the xml file id for the full rates xml file.capture1.png
4. Value:
GET https://hosted.datascopeapi.reuters.com/RestApi/v1/Extractions/ExtractedFiles('V111111111=')/$value
We pass in the extracted file id from the previous call. We download the content of the file.
We have noticed on a few occasions that the response we received from the call number 3 (Files) contained fields with default values. One of them was LastWriteTimeUtc, which was set to "01/01/0001 00:00:00 +00:00". We were wondering what can be the cause.
Unfortunately we can't provide any notes as they were overridden by the next extraction and we don't store them. Please let me know if you need any other information.

{kind=link}