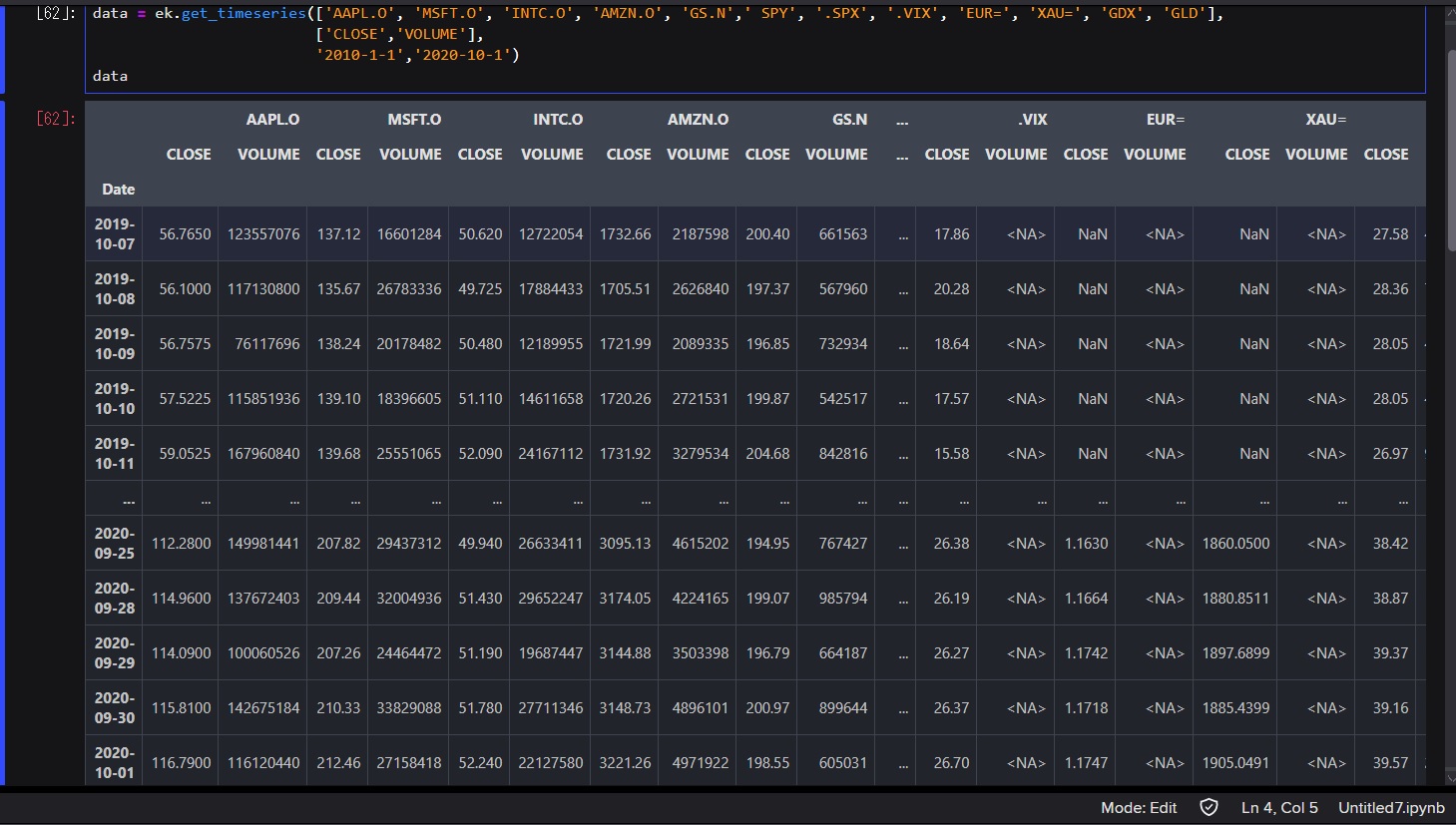
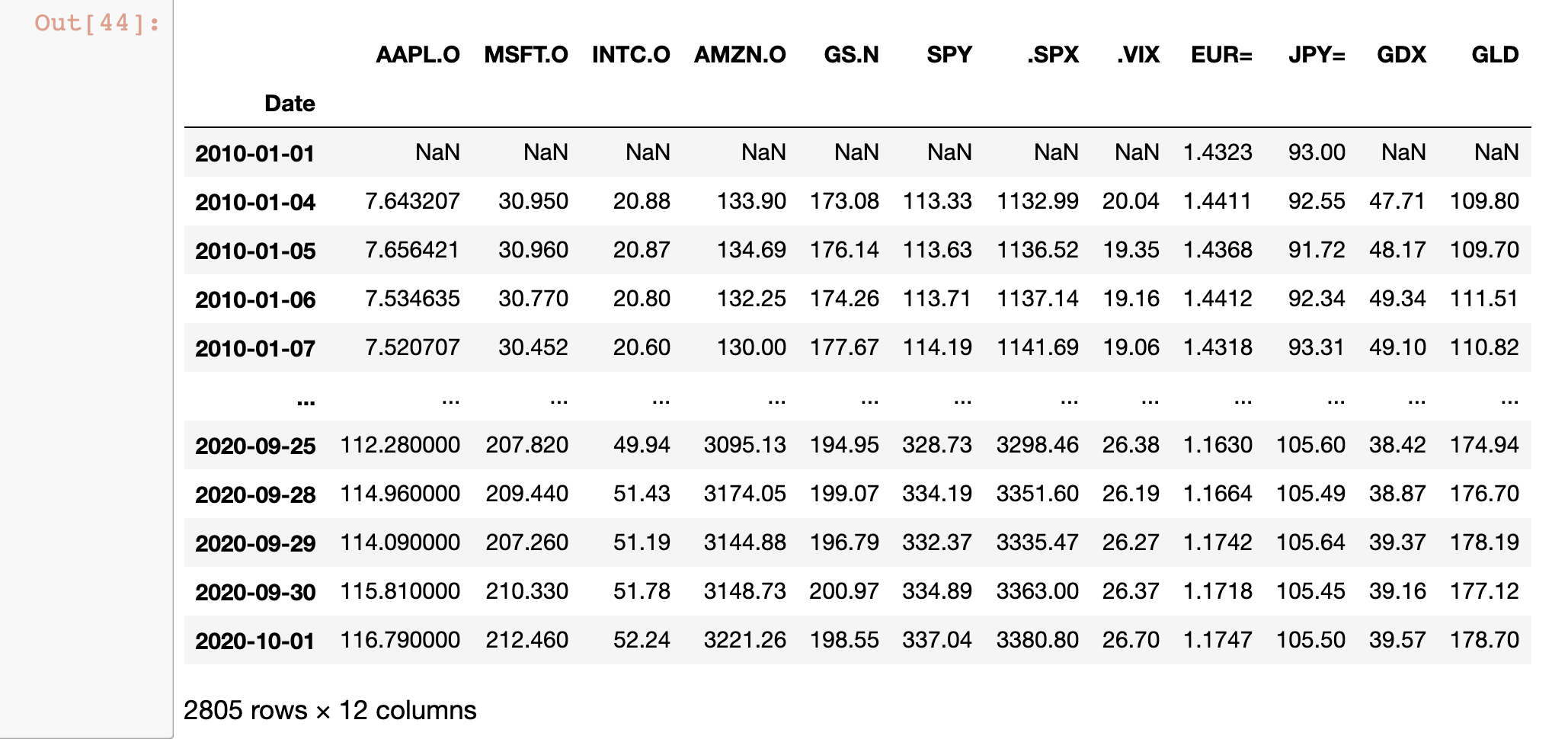
Please tell me the contents of the following csv file introduced in this book and the EIKON API Code to get the same data. This book does not describe how to obtain the data, but instead provides EIKON data as a sample file. With "get_timeseries" I couldn't reproduce the exact same data.
- Book Name : Python for Finance, 2nd Edition [Book] - O'Reilly
- CSV : tr_eikon_eod_data.csv (Data excerpt)

- Code I created (The date data is slightly different from the sample.)
data = ek.get_timeseries(['AAPL.O', 'MSFT.O', 'INTC.O', 'AMZN.O', 'GS.N',' SPY', '.SPX', '.VIX', 'EUR=', 'XAU=', 'GDX', 'GLD'], ['CLOSE'], '2010-1-1','2020-10-1') data
- Result (Where should I modify the code to get the same result as this?)
ValueError: The truth value of a DataFrame is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
- Related code & Result (Add column)